Discovering Null Byte Injection Vulnerability in GoAhead
How I found a zero-day in an embedded web server while testing problems for PlaidCTF 2021.
- The Casablanca Camera Caper
- Javascript Templates 😬
- Extension Handling
- Over-Protective Chrome
- Aftermath
- Acknowledgments
I had the privilege of testing problems for PlaidCTF 2021, where I spent a decent amount of time on the Carmen Sandiego series of challenges. The basic premise is that the player can manipulate sensor and camera snapshot values that are visible to an admin on the web interface. Somehow, the admin must be tricked into divulging the flag at /cgi-bin/flag.
GoAhead is the web server for this problem and, according to their website, is the “worlds most popular embedded web server” used in “hundreds of millions of devices”. The intended solution was to exploit a zero-day in GoAhead where the Content-Length response header would incorrectly state the amount of data in the response under certain conditions. I happened to come across a different zero-day that allows an attacker to choose an arbitrary extension for a file, which turns out can be very useful. For instance, it would have made solving the Carmen Sandiego problems much easier if Chrome allowed encoded null bytes in URLs.
The Casablanca Camera Caper
In this version of the problem, the player can upload “snapshots” that are visible to the admin on the main dashboard.
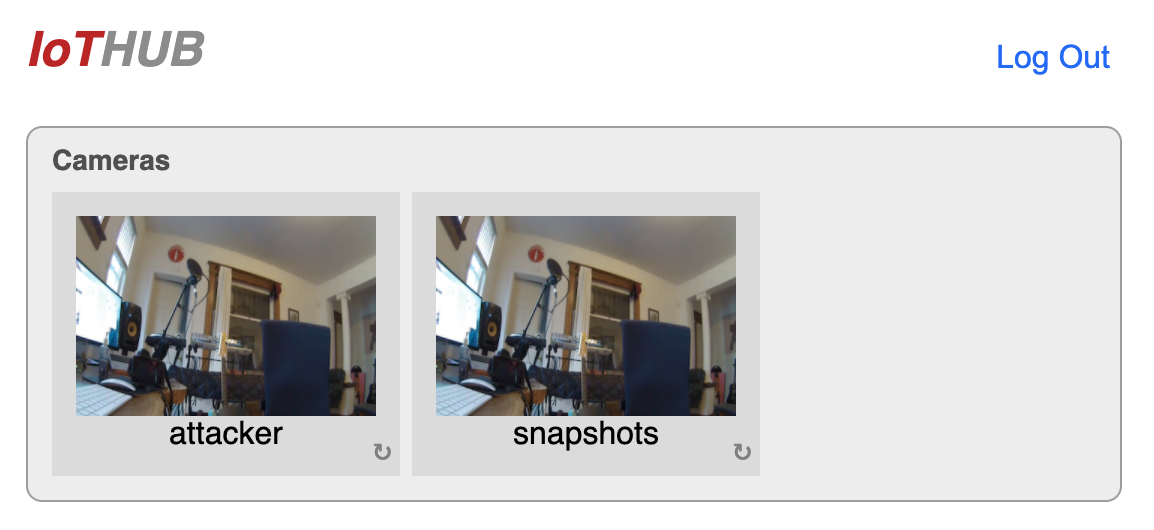
The snapshot names are protected by a solid regex:
KEY_REGEX = r"([a-z]{1,512})"
But, the contents of the snapshots have no limitations other than a generous maximum size of 1MiB. The player is also allowed to specify a URL for the admin to visit once they have logged in and seen the snapshot view. So why can’t we just upload a script that fetches and sends the script to us by having the admin visit the snapshot URL? Content Security Policy of course!
Content-Security-Policy: default-src 'self'; script-src 'nonce-a3bdb41f7d7b5edcf53b185662585b42'; img-src *
In English: only images are allowed to interact with external origins, all scripts must contain a unique nonce attribute that changes every time the file is served, and everything else (like iframes) must be from the origin of the challenge app.
The biggest obstacle here is the nonce-based script policy. It’s also interesting because GoAhead does not provide this capability by default, it was added in a patch by the challenge author. This made it the focus of my exploitation efforts.
Javascript Templates 😬
The homepage (index.html) requires a nonce to be able to load its script (main.js). So let’s see how the web server knows to put a nonce in the right place by looking at the raw, non-served version of index.html:
<script nonce="<% nonce(); %>" src="main.js"></script>
Interesting! I attempted to do a similar thing in a snapshot with an inline script:
<script nonce="<% nonce(); %>"> alert(1);</script>
This didn’t work… Nothing was replaced by the web server. At this point I RTFMd and found Javascript Templates. GoAhead’s documentation explains that .jst files are processed by a JST handler that looks for delimiters (<% %>), executes the specified script, and then replaces the contents with the result of the script. There is one default function, write(). The author of this challenge add the nonce() function as a part of their nonce-based CSP implementation.
If the JST handler is meant for .jst files, why did it work on index.html? Turns out you can tell GoAhead which handlers you wannt for different extensions when specifying routes which is what the challenge author did:
// file: "/etc/route.txt"
route uri=/ extensions=html handler=jst
If the snapshot names could have a period then a snapshot could have a .html extension to get a valid nonce!
As an aside, Javascript templates do not seem very safe. I’m curious how they’re used in legitimate applications and whether or not those uses pose any risk.
Extension Handling
I tried a few things to see if I could trick GoAhead into thinking my snapshots had an HTML extension like ending the filename with html without the period. It was a long shot and nothing worked. But this is meant for a CTF! Maybe there was something wrong with how GoAhead parses extensions and I needed to dive into the source. So that’s what I did.
This is how GoAhead gets the extension from a request (Source):
// file: "http.c"
/* [/path] */
if (*tok) {
/*
Terminate hostname. This zeros the leading path slash.
This will be repaired before returning if ppath is set
*/
sep = *tok;
*tok++ = '\0';
path = tok;
/* path[.ext[/extra]] */
if ((tok = strrchr(path, '.')) != 0) {
if (tok[1]) {
if ((delim = strrchr(path, '/')) != 0) {
if (delim < tok) {
ext = tok;
}
} else {
ext = tok;
}
}
}
}
At this point I figured the request URL must have been decoded, otherwise it wouldn’t be able to call strrchr() with . and / delimiters.
So… what if there was a null byte in the URL? Null byte injection is a well-known technique, but this isn’t really a place I would expect to be useful. In my mind there were a couple possibilities:
- Dangerous URL encodings like
%00aren’t allowed. An error will be served - Dangerous URL encodings like
%00aren’t decoded. A request for/example%00.htmlwill attempt to serve/example%00.html - If the
%00is decoded, in a request for/example%00.htmlthe extension will simply be cut-off. There will be no extension and GoAhead will attempt to serve/example.
Nevertheless, I uploaded a snapshot with the name example with the following contents:
<script nonce="<% nonce(); %>"> alert(1);</script>
Then I made a request for /data/snapshot/example%00.html and to my amazement the nonce was there!
$ curl 'http://localhost/data/snapshot/example%00.html' -H 'Cookie: -goahead-session-=::webs.session::9bf107c4ed34c7320fb37d2cb400b85f'
<script nonce="7616bb8945f2eaf7f228871aed78c909">alert(1)</script>
Despite the challenge bot using Puppeteer (a Chrome automation tool), I was testing with Firefox. I navigated to the same URL and it worked!
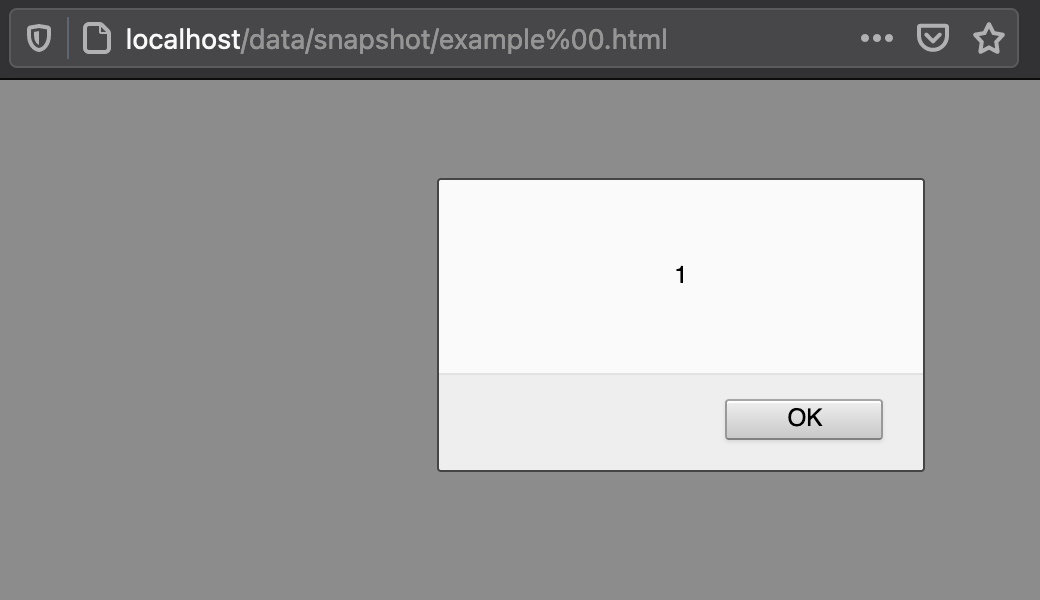
This meant that my assumptions were incorrect. The URL is parsed as having the .html extension, meaning the JST handler is invoked. But when it is time to fetch the file, the null byte comes into play and example is grabbed instead of example%00.html. We get the best of both worlds! This is also pretty serious because it manys any route that depends on an extension to determine the correct handler can be bypassed!
Over-Protective Chrome
I was ecstatic and confidently ran my solution on the live test server hosted by the author to get the flag.
Nothing happened.
I ran it again.
NOTHING.
Confidence shaken, I ran it locally and received this error from Puppeteer:
victim_1 | (node:30) UnhandledPromiseRejectionWarning: Error: Protocol error (Page.navigate): Cannot navigate to invalid URL
victim_1 | at /home/bot/node_modules/puppeteer/lib/cjs/puppeteer/common/Connection.js:208:63
victim_1 | at new Promise (<anonymous>)
victim_1 | at CDPSession.send (/home/bot/node_modules/puppeteer/lib/cjs/puppeteer/common/Connection.js:207:16)
victim_1 | at navigate (/home/bot/node_modules/puppeteer/lib/cjs/puppeteer/common/FrameManager.js:108:47)
victim_1 | at FrameManager.navigateFrame (/home/bot/node_modules/puppeteer/lib/cjs/puppeteer/common/FrameManager.js:91:13)
victim_1 | at Frame.goto (/home/bot/node_modules/puppeteer/lib/cjs/puppeteer/common/FrameManager.js:416:41)
victim_1 | at Page.goto (/home/bot/node_modules/puppeteer/lib/cjs/puppeteer/common/Page.js:789:53)
victim_1 | at /home/bot/dist/index.js:34:20
victim_1 | at Generator.next (<anonymous>)
victim_1 | at fulfilled (/home/bot/dist/index.js:5:58)
victim_1 | (Use `node --trace-warnings ...` to show where the warning was created)
victim_1 | (node:30) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). To terminate the node process on unhandled promise rejection, use the CLI flag `--unhandled-rejections=strict` (see https://nodejs.org/api/cli.html#cli_unhandled_rejections_mode). (rejection id: 1)
victim_1 | (node:30) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
I did some digging and confirmed that Chrome does not allow encoded null bytes in URLs. This is a pretty good thread on the subject that discusses some of the differences in how URLs are parsed across different applications. Unfortunately that meant I wouldn’t be able to get the flag using this exploit :(
Maybe there was a way to bypass how Chrome parses URLs? That sounded extreme and I had already spent a lot of time getting to this point, so I just asked the challenge author. He let me know that I wasn’t anywhere close to the unintended solution and that I should report my findings to GoAhead.
Aftermath
GoAhead has a dedicated email for security reporting that was easy to find. The security contact also responded very quickly with a more detailed explanation of the vulnerability than I worked out and the strategy for patching. The next day it was patched. Here is how he explained it:
Definitely not correct handling. We’ve prepared an update that does not decode %00 to NULL. Our GoAhead 2 & 5 versions do not have this issue as we explicitly reject %00. We are back porting this to version 4 which is our GPL and evaluation version.
The interpretation of the route extension property is NOT for file extensions, but URL extensions. These are often the same, but not always.
So the request:
curl http://127.0.0.1/example%00.jstIs actually asking for the URL that ends with html, which this URL does. Not for the file that ends with “.jst”. i.e. it is correct to invoke the JST handler as the URL has a ‘.jst’ extension.
The issue is that the resolved physical file name does not match the URL of “example%00.jst”. i.e. the NULL truncates the file name and an unexpected file name is served.
Our patch preserves the %00 and so the filename then matches the URL. If there is a file named “example%00.jst” literally, then it will be executed correctly.
To exploit, it would need to be coupled with another exploit or weak configuration. i.e. you need to have a file uploaded which has JST which should not be executed as such. Using a URL as “/“ with extensions=“jst” handler=jst is okay, provided you do not allow upload to the same directory. Upload should only be allowed to a restricted directory.
The GitHub issue can be found here: https://github.com/embedthis/goahead-gpl/issues/5
Props to GoAhead for handling this so well. As I found out when writing my previous blog post two years ago, some companies are not nearly as responsive to vulnerability reports.
Moving forward, I may try to see if I can get this filed as a CVE. I don’t know much about the how that works, but I think this would a good opportunity to learn.
Thanks for reading!
Acknowledgments
- Thanks to @thebluepichu for developing this challenge and encouraging me to report my findings
- Thanks to Michael O’Brien for being a pleasant and responsive point of contact at GoAhead